Nesse post mostrarei como elaborar mapas temáticos no Quantum Gis.
Mapas temáticos são úteis quando deseja-se apresentar geograficamente variáveis oriundas de algum banco de dados.
Para o exercício contido aqui é importante que o leitor tenha reproduzido os exercícios dos posts anteriores (Parte 1 e Parte 2), assim a compreensão será completa.
Elaborando mapas temáticos.
Para executar esse exercício faça o download da malha digital de columbus. No arquivo Dados Columbus.zip os principais itens são:- Columbus.shp
- Dados.dbf
Lembrando que para trabalhar com mapas no formato digital é necessário pelo menos três arquivos: *.shp, *.shx e *.dbf. Todos com o mesmo nome, por exemplo, Columbus.shp, Columbus.shx e Columbus.dbf.
Além desses arquivos, pode ser interessante adicionar a tabela do mapa outras variáveis. No caso da malha Columbus.shp a tabela com os dados chama-se Dados.dbf.
O Quantum Gis aceita a importação de arquivos em diversos formatos, o mais comum é o formato *.dbf.
Isso não é uma restrição a sua análise, já que softwares como Excel, Access, Open Office, SPSS, SAS, R, etc. são capazes de converter suas bases nativas para o formato *.dbf.
Particularmente, o software que eu mais gosto para fazer esse tipo de conversão é o StatTransfer (o problema é que ele não é gratuito).
Realizando o JOIN entre as tabelas do mapa e base de dados.
Para realizar a união (join) entre os dados (Dados.dbf) e a malha (Columbus.shp) é necessário inicialmente que ambos os arquivos possuam uma variável chave essa variável será responsável pela determinação de quais observações da base de dados (Dados.dbf) estarão associadas aos polígonos da malha digital (Columbus.shp).
É importante que as variáveis tenham o mesmo formato, isso é, se uma é caractere a outra variável deverá ser caractere, se é numérica, ambas devem ser numéricas. Se uma tem 6 dígitos a outra também deverá ter seis dígitos.
Graficamente, podemos representar da seguinte forma:

Uma boa prática é utilizar variáveis chave que sejam numéricas. Assim evitamos problemas com acentuação, letras maiúsculas, minúsculas, etc..
Usualmente, as principais variáveis chave são:
- Código do município.
- Código do setor censitário.
- CEP.
No caso do nosso exercício, a variável chave chama-se POLYID em ambos os arquivos Dados.dbf e Columbus.shp.
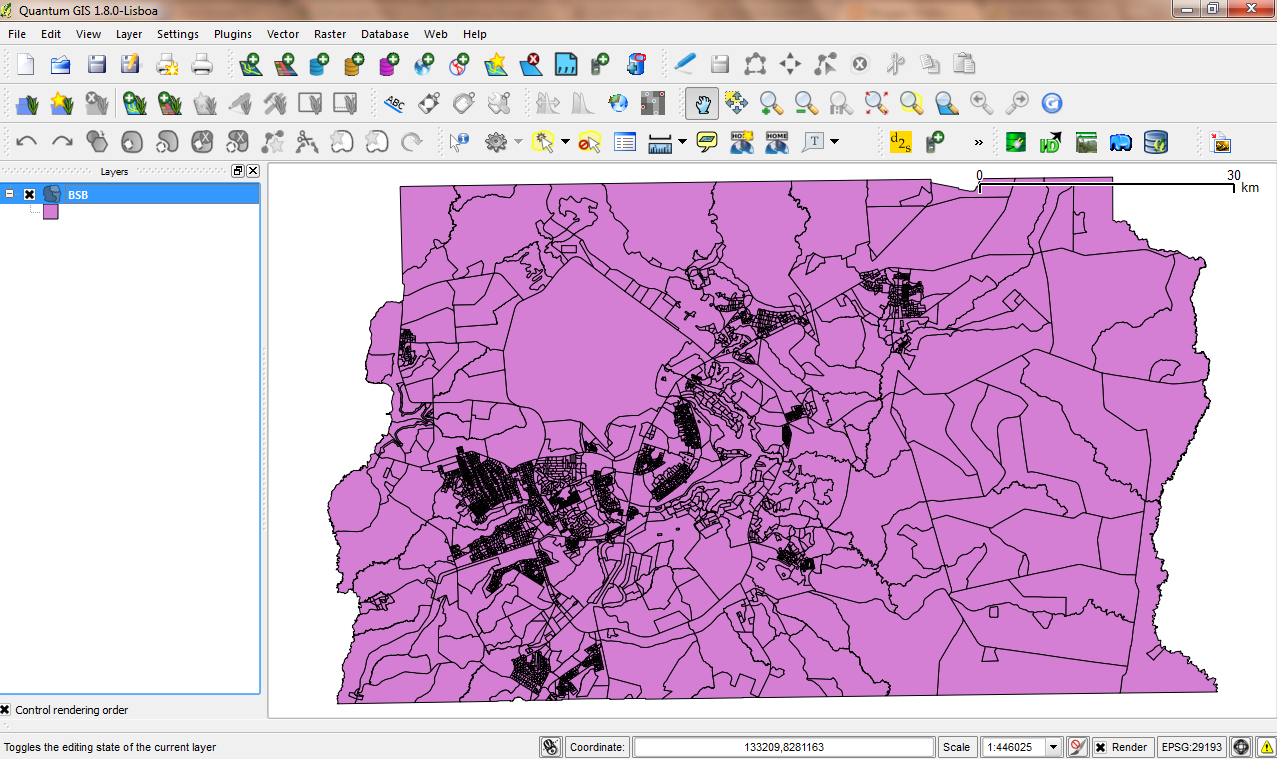
Adicionando a malha no ambiente QGis.
Como demonstrado nos posts anteriores, admita que a malha já esteja projetada e adicionada no ambiente QGis.Graficamente, devemos ter algo como:

Em seguida devemos fazer a junção (join) entre os dados (Dados.dbf) e a malha (Columbus.shp) para isso arraste o arquivo Dados.dbf para o ambiente QGis. Essa base aparecerá no campo Layers como mostrado abaixo:

Em seguida, clique com o botão direito do mouse sobre o Layer columbus e escolha a opção Properties. Na tela que surge clique na aba Joins.

Clique no botão "soma" e assim surgirá o seguinte formulário:

A variável chave em ambos os campos é POLYID. Em seguida clique no botão OK:

Finalmente, clique no botão Apply e posteriormente no botão OK. Para saber se as variáveis foram adicionadas corretamente, clique com o botão direito do mouse sobre o Layer columbus e escolha a opção Open Attribute Table. Se o procedimento foi realizado corretamente, haverá novas variáveis na base de dados do Layer columbus. Essa malha com novas variáveis pode ser salva, evitando assim a repetição de procedimento no futuro.
Pintando o mapa.
Agora, podemos visualizar a distribuição da criminalidade em Columbus, para isso, faremos um mapa temático.O primeiro passo é clicar com o botão direito do mouse sobre o Layer columbus e escolher a opção Properties. Na tela que surge escolha a aba
Style:

Escolha então a opção Graduated:

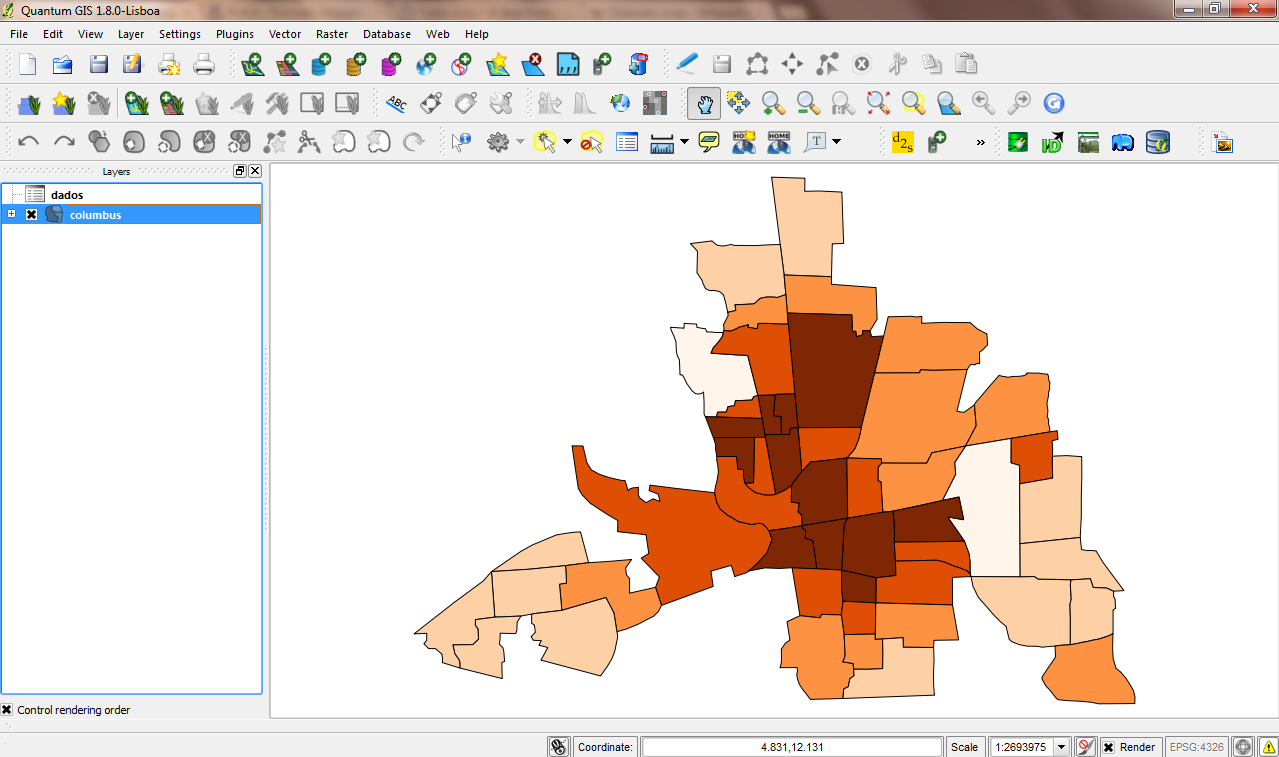
Na caixa Column escolha a variável que desejamos representar espacialmente (aqui será a variável CRIME), na caixa Mode há algumas opções, aqui escolheremos a opção Natural Breaks (Jenks) que minimiza a variância interna em cada uma das classes. O número de classes escolhidas aqui é 5 e pintaremos o mapa na escala de laranjas:

Clique no botão Apply e posteriormente no botão OK. O resultado é o seguinte:
Para exportamos o mapa final para um formato de imagem procedemos da seguinte forma: clique no botão New Print Compose:

Na tela que surge, clicamos no botão Add New Map e com o mouse definimos onde gostaríamos que o mapa estivesse na imagem:

Usando o mouse representamos onde o mapa deverá estar:

Para adicionar a legenda, clicamos no botão Add new legend:

Novamente usando o mouse posicionamos onde a legenda deverá estar. Por fim usando a janela Item properties podemos editar as opções da legenda:

Para salvar o mapa fazemos File → Export as PDF.... É claro que você pode salvar a imagem em outros formatos também.